







Alexa Slot Only Sample Utterance – What it is and why use it
The Great Mystery
You may have heard or gotten a recommendation from the team behind Amazon Alexa to “create a Separate Intent for Each Slot-Only Sample Utterance: Slots in isolation will have higher accuracy if they have their own intents.” Basically, create an intent with only one utterance, which is just a slot value of that particular entity. But why? It’s not explained very well at all, as any google search can attest to. So what does that mean, and what does it do? It is no secret that voice recognition is a very tricky thing. The amount of variance that goes on in everyday speech is staggering. Even humans have issues understanding one another when too much “communication noise” arises.
Voice skills are no different, and in order to most effectively recognize what is being said, most of them use machine learning behind the scenes to train on the vast amounts of data. In most cases, this data is provided in the form of utterances and entities. As a general rule of thumb, the more specific the utterance, the easier it is to recognize it. But we can’t always be as verbose as we want to. The goal is to reduce the friction between the user and the skill.
However, the looser we become, the worse voice recognition gets. Take for example the Unofficial Destiny Voice Companion, and an issue that I personally ran into.
Give me an example
The warlock class in Destiny 2 has access to a set of armor where every piece’s name is “Tesseract Trace IV”. Straightforward enough. But very often it would occur that I would say “equip tesseract trace four”, but the skill would hear “equip tesseract trays for”. Not surprising, considering that the only difference between the pronunciation of “trace” and “trays” is the voicedness of the last sibilant “s”/”z”, not to mention “four”/”for”, which have merged in some dialects of American English. None of this even takes into consideration non-native speakers of English.
Applied theory
Now, this is where these “entity only intents” come into play.
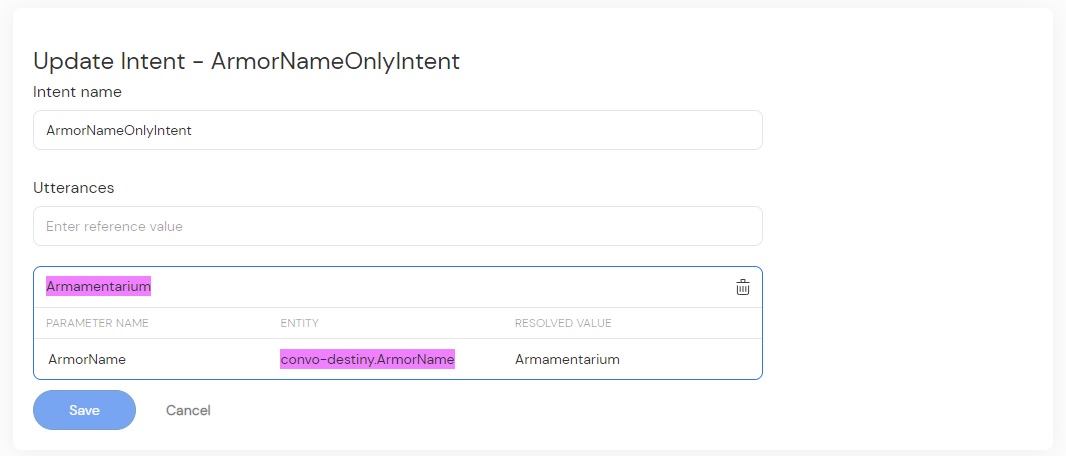
For example, in the UDVC, I have two intents: EquipWeapon and EquipArmor. They consist of several utterances that all amount to basically “equip <ItemName>”. They are more or less complex, but that’s the general gist.
To improve the accuracy of voice recognition, I have added another intent called EquipItemIntent. Its utterances consist of variations on the phrase “I want to equip an item”. When a user triggers this intent, I lead them to another step in the conversation. There, I only consider the user saying the name of any given item. This is where our “entity only intents” come into play.
Both WeaponNameOnlyIntent and ArmorNameOnlyIntent have one single utterance with only one slot of the corresponding type — WeaponName and ArmorName respectively. So how does this help?
The theory behind it is that there is no “chaff” around the slot to listen to — assume whatever the user says can be matched against a given entity, which improves accuracy. If the skill thinks I said “tesseract trays for”, it can adjust this result to match either a weapon name or, more appropriately, armor name, which amounts to Tesseract Trace IV.
Note that, as any other method, this isn’t perfect. It introduces some interference between the user’s end goal and the user themselves. However, for finicky situations, this is a preferable tradeoff, and is a much more pleasant experience than for the user to have to repeat themselves twice or thrice over. And there you have it. The fabled Alexa Slot Only Sample Utterance explained. To recap, they are simple intents with only one utterance that consists of only one slot with the value you wish to encapsulate. They serve to improve the accuracy of voice recognition during your skill’s flow. Hopefully this was useful to you. If you want to read more about the Destiny Alexa skill that I made, you can do so here.

Related posts

A Dead Simple RAG Setup for WordPress: AI Chatbots for Small Websites
Discover how to set up a dead-simple RAG-based AI chatbot on your small WordPress website. With Convoworks, you can easily enable a chatbot that retrieves information directly from your pages, enhancing user experience with minimal setup. Perfect for small sites looking to leverage GPT-powered chat functionality in minutes!
VIEW FULL POST
How to Modify Your robots.txt to Prevent GPTBot from Crawling Your Site with Convoworks
Introduction Ensuring that your website’s content is accessed on your terms is essential. With an increasing number of web…
VIEW FULL POST


