








Leveraging Semantic Search in WordPress: Creating Embeddings with Convoworks, Pinecone, and OpenAI GPT
In an era of information explosion, making sense of vast amounts of data has become increasingly complex. Welcome to the realm of embeddings, vector databases, and semantic search. Unlike traditional search methods that rely on direct text matching, semantic search seeks to understand the meaning and context behind a query, delivering more precise results. This article delves into the intricacies of semantic search and guides you on implementing it for your WordPress site using Convoworks, Pinecone, and OpenAI GPT.
If you’re unfamiliar with semantic search, consider watching the excellent free tutorial at DeepLearning.ai
Understanding Embeddings, Vector Databases, and Semantic Search
Embeddings transform words or phrases into vectors of real numbers at a high level. This numerical representation encapsulates the semantic essence of the content. Vector databases, such as Pinecone, store and manage these embeddings, enabling efficient similarity searches. Semantic search endeavors to understand the intent behind a search query rather than simply seeking keyword matches, providing a nuanced, context-aware search experience.
For creating embeddings, we use the text-embedding-ada-002 OpenAI model, while Pinecone serves as our vector database. Pinecone’s free starter plan allows storage for nearly 100,000 vectors.
Setting up Your Pinecone Account
- Navigate to the Pinecone website and sign up for the free plan (sufficient for this example).
- Create a new Index with 1536 dimensions (determined by the text-embedding-ada-002 model we’re using for creating embeddings) and set metrics to cosine.
- Once registered and the index created, make a note of your API key. This will be necessary for integration with Convoworks.
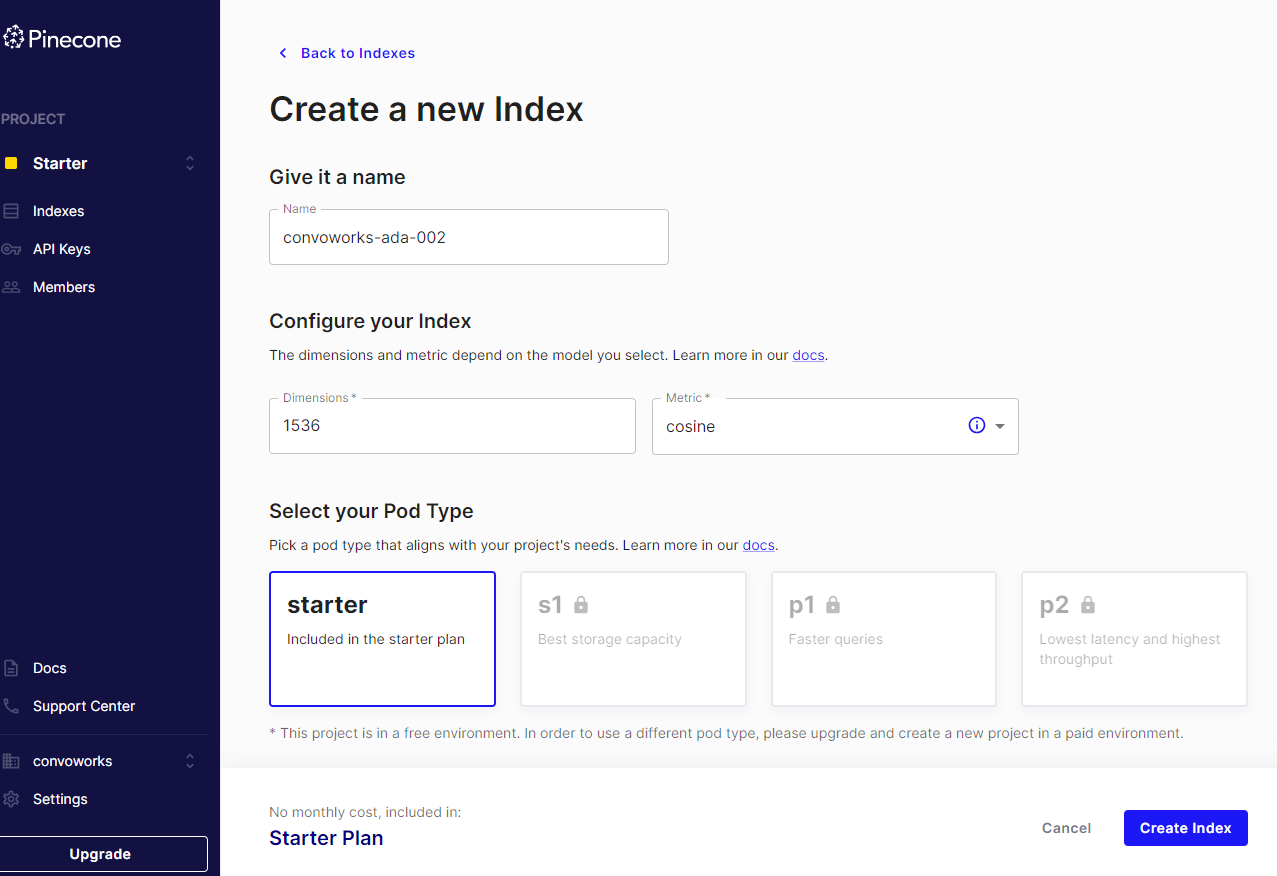
Importing and Configuring the Convoworks Service
We’ve prepared two Convoworks service definitions for this purpose. The first, GPT Embeddings Worker, contains the primary embeddings logic and a chat utility for manual testing. The second, GPT Embeddings Scheduler, is a straightforward service connecting to the init WordPress action, scheduling hourly monitoring of newly updated posts for re-indexing.
GPT Embeddings Worker (JSON) GPT Embeddings Scheduler (JSON)
- Install and activate Convoworks WP (available on WordPress.org) and the Convoworks GPT Package plugin (found on GitHub).
- In wp-admin, go to Convoworks WP, click Create new service, choose Import from file, upload the service definition, and click Submit.
- After importing, navigate to the Variables view. Here, input your Pinecone API key, Pinecone base URL (found in your Pinecone Index dashboard), and OpenAI API key.
- Repeat this process for both services. Note that the GPT Embeddings Scheduler service has no variables to configure.
At this point, the services won’t function until you activate the WordPress Hooks platform for them. You might choose to postpone this step until after testing and customizing to your preferences.
Additional Configuration Values
Beyond the API-related settings covered above, several other values can be adjusted via the Variables view:
POST_TYPES: An array of post types for inclusion in your semantic search. This variable combines with theget_posts()function when retrieving posts for indexingTIME_LIMIT: For first-time runs, the embedding process may take a while. Adjust this value to modify the time limit set byset_time_limit().STOP_WORDS: Stop words help clean content before indexing in the vector database. These common words, such as “all”, “am”, and “and”, don’t significantly contribute to semantic value. In our toolset, they aren’t mandatory, so it defaults to an empty array. Setting this value to${null}will use predefined stop words.
Testing the Service: Chat Utility
Once fully enabled, the service will operate in the background, defaulting to once per hour using the WP-Cron. However, instead of waiting for it to run automatically, developers should have the ability to manually trigger and test each functionality it offers. For this reason, we’ve added a simple utility chat logic to the Worker service. This allows you to embed a single post (by ID), embed all posts, and test search queries. Additionally, this utility offers a foundational base for customizing and adding more commands as you see fit.
To begin, navigate to the Test view in your GPT Embeddings Worker service and type “embed 123” (ensure you replace this with an actual post ID from your website). If this process is successful, you might want to type “embed all”. However, before running “embed all”, take a moment to review the search criteria we use to filter the posts you wish to index.

After indexing a sufficient number of posts, you can query them to observe the search results returned. In our test view, type “search [your search query]”. If everything is functioning correctly, you should see results returned from Pinecone, including post ID, post title, and matching score, followed by a GPT-generated answer.
It’s important to note that this chat utility is not a sophisticated AI chatbot. It simply uses a plain text filter (stripos()) to match your input. Alongside the Debug panel adjacent to the test chat, if you encounter issues while using the utility, you can enable a log file for a more detailed troubleshooting process.
Service Walkthrough: Creating and Updating Embeddings
The Embed Post reusable fragment contains logic to prepare and index a single post. It expects the ${POST} variable to be defined and for it to contain the loaded post.
The first step is to prepare and clean up the content by stripping tags, punctuations, etc. The tokenized content is then sent to the OpenAI Embeddings API, which returns the post’s vector representation.
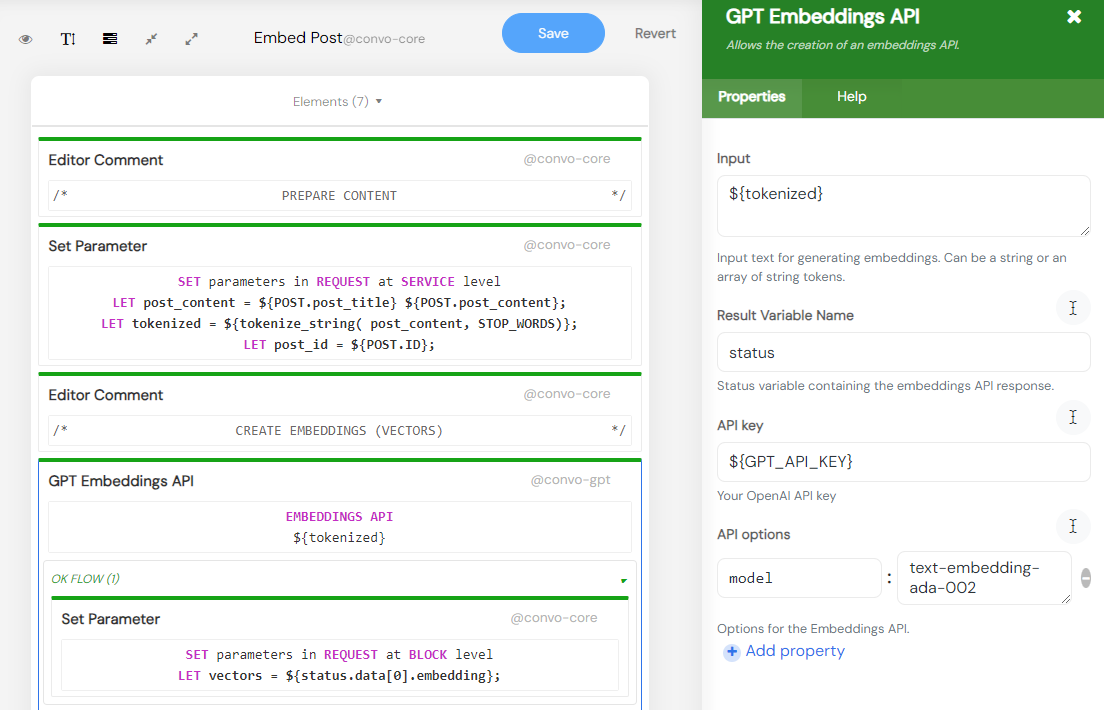
The final step involves attaching metadata to it and sending it to Pinecone for storage. Metadata can be used to further filter your query requests and also helps identify the source post from which it was generated.
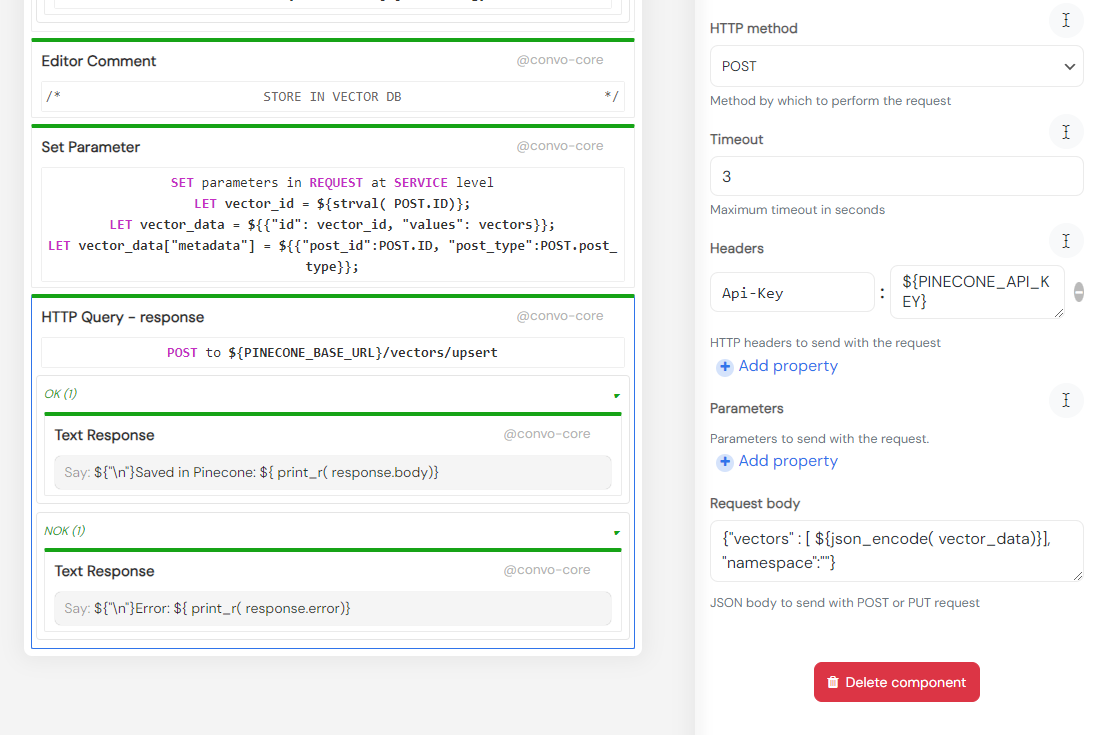
In this example, we store the complete article as a single vector. This is a straightforward technique suitable for many use cases. If you have long posts that cover multiple distinct topics, you might want to divide them into chunks and index each chunk separately. Keep in mind that you have the option to set metadata (e.g., post_id), enabling you to load the necessary post to provide the AI with the appropriate context when generating an answer.
Embedding content at a glance:
- Data Preparation: The service preprocesses post content before creating embeddings, removing any superfluous data.
- Embedding Creation: Using OpenAI GPT, the service produces embeddings for each post.
- Sending to Pinecone: The created embeddings are then dispatched to your Pinecone vector database for storage and subsequent search operations.
Service Walkthrough: Semantic Search & Generating Response
The primary role of the GPT Embeddings Worker service is to index your data. Once indexed, this data can be utilized in various ways. For practicality, we’ve included a semantic search function in our utility chat, allowing you to quickly assess what the vector database returns. Furthermore, we’ve incorporated a feature to generate responses, offering a comprehensive demonstration of how these advanced techniques function in practice. As illustrated in the screenshot below, the search term undergoes preparation and vectorization in the same way we did for embedding posts. It’s then sent to the Pinecone query endpoint via an HTTP client. The results from Pinecone are integrated as contextual data in the GPT call (in the form of additional system messages). This process ensures the AI can craft a relevant response based on the given context. This example also showcases the versatility of defining contextual information when employing GPT in Convoworks. Examine the Home step within the service and the Search processor; all the steps mentioned are visible there.
Semantic search at a glance:
- Data Preparation: The search query is readied using the same method employed for post content preparation.
- Embedding: With OpenAI GPT, the service formulates embeddings for the search query.
- Querying Pinecone: These embeddings are dispatched to the Pinecone API query, returning results (metadata with post IDs).
- Generating an Answer: Relevant posts are loaded (and converted to markdown to minimize size) and relayed as supplementary context to the GPT Chat Completion API, which produces a response. By default, our example employs the
gpt-3.5-turbo-16kmodel, known for its expansive context space and accessibility to users on the free plan. If you have the capability, you might experiment with thegpt-4model. It performs more efficiently, though its context is halved. For more information on the distinct OpenAI models, refer to the provided link.
Service Walkthrough: Enabling Automatic Content Indexing
As content is frequently added and modified, there arises a need to periodically run a procedure that will re-index the updated content. To activate this, you must enable the WordPress Hooks platform in the Convoworks Configuration view. You don’t need to modify any settings; simply activate it for both services. By default, the GPT Embeddings Scheduler service will schedule the task to run hourly. For other scheduling options, consult the official WordPress documentation.
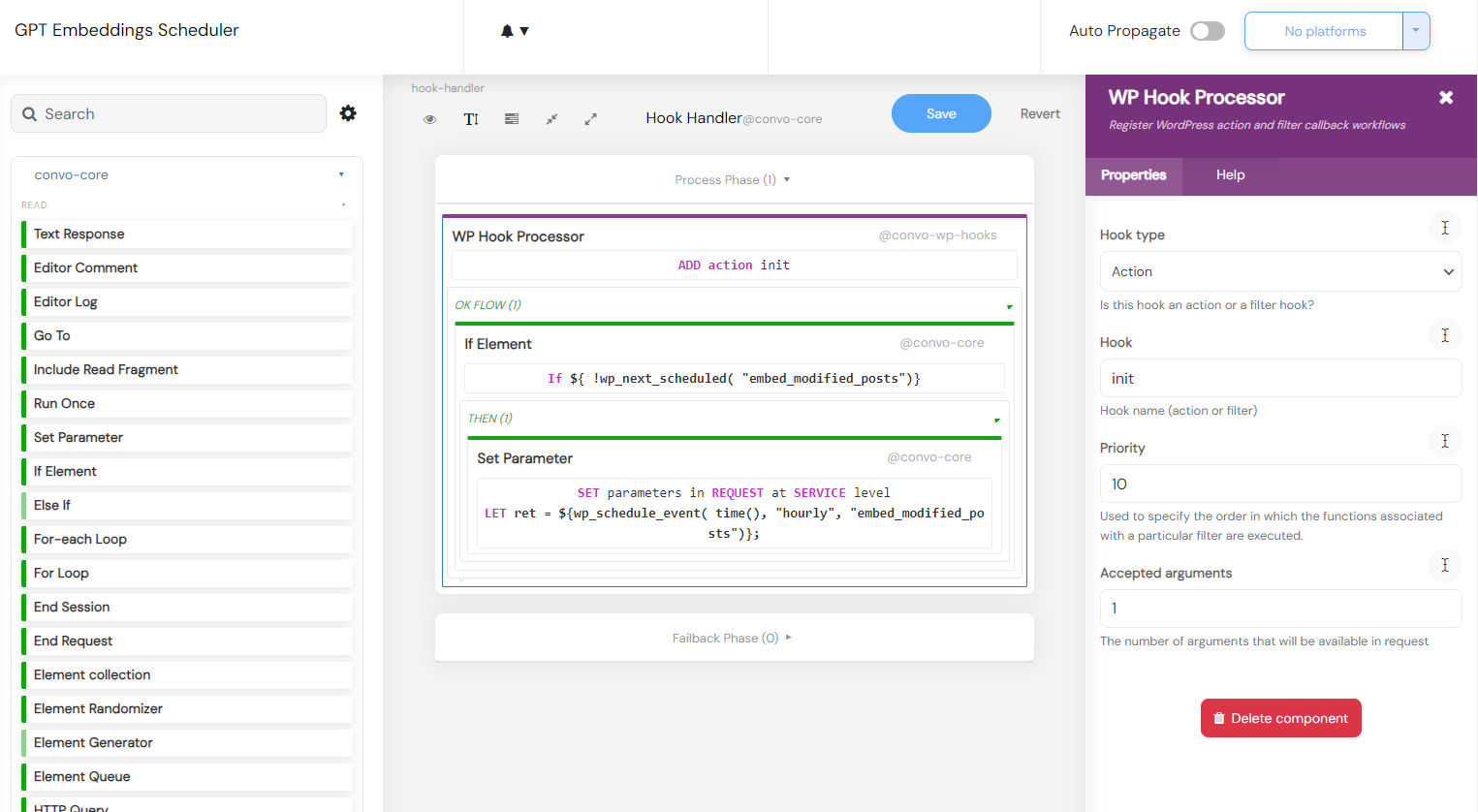
Whenever the embed_modified_posts action is invoked, the Hook Handler step in the GPT Embeddings Worker service is activated. This handler will retrieve the modified posts and utilize them in our Embed Posts fragment. Observe how the Hook handler leverages the embed_posts_last_run option to fetch posts that have been modified since the task’s last execution. In this example, we are retrieving posts created or modified within the last six months.
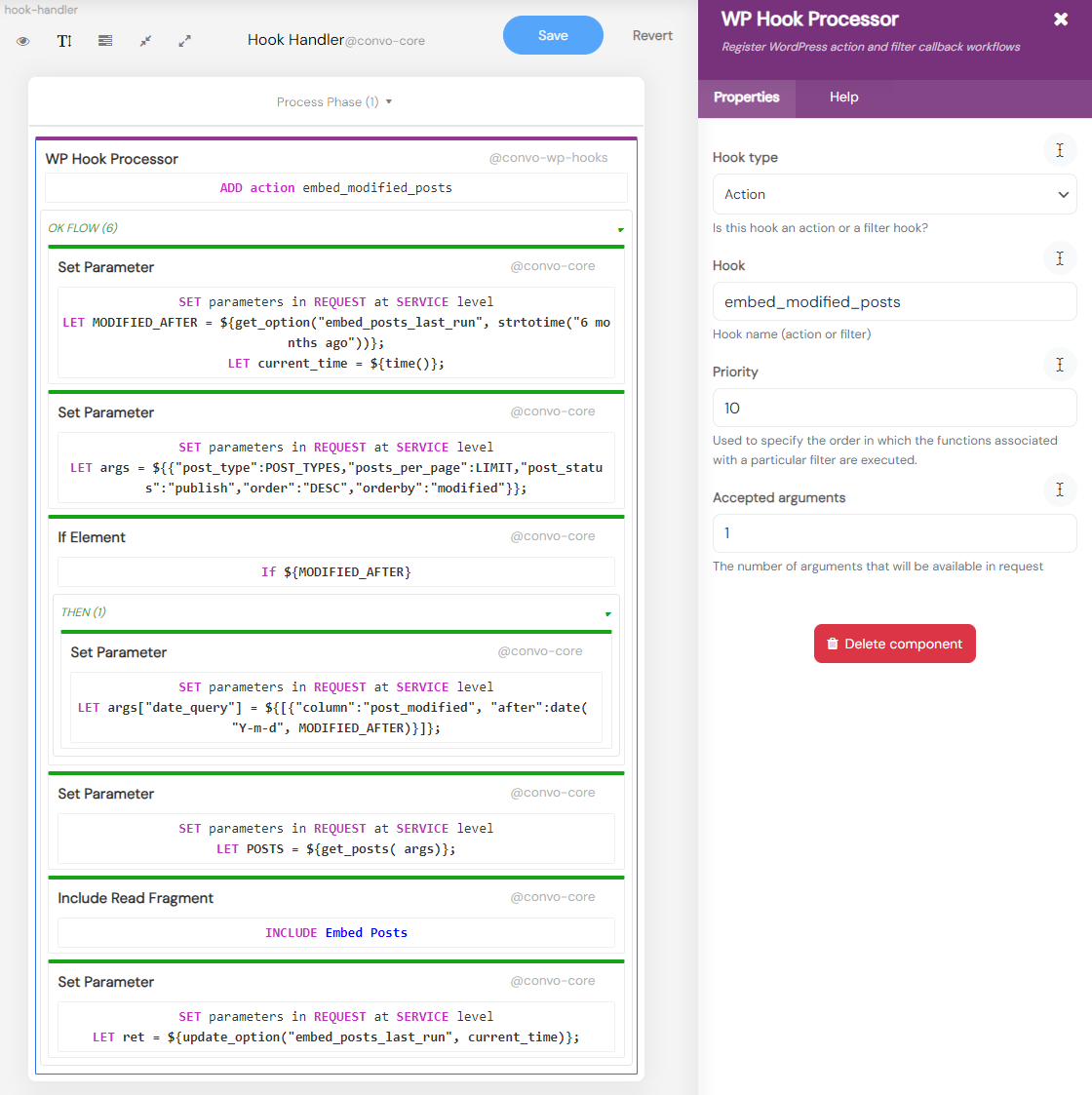
For this process to operate automatically, ensure you activate the WordPress Hooks platform in the Configuration view for both services.
See it in Action
We’ve set up a simple demo chat that mirrors the search functionality from the utility chat mentioned earlier. Try it out by clicking on the chatbox at the bottom right of this page. This example service is also available for download. To enable it on the front end, you need to activate the Convo Chat platform in the service configuration. Afterward, you can use the shortcode [convo_chat service_id="your-service-id" title="Awesome Title"]. We hope you find it engaging.
Please note that the answers might not be generated instantaneously. While we do make several API calls during the process, the majority of the delay stems from the response generation by GPT. Bear in mind that this chatbot doesn’t track the conversation context; its primary function is to address your immediate question.
GPT Embeddings Q&A Chat (JSON)
Customizations to Consider
The example services we’ve provided are tailored to the specific needs of the Convoworks website. We’ve kept it this way to illustrate how it appears in a specific use case. Below are several aspects you might want to customize to suit your requirements.
Main Prompt & Convoworks: In the GPT Chat Completion API v2, we set a main instruction for the bot. This instruction provides foundational details about us, which remain consistently present in the conversation context. You should adjust these instructions to reflect your specifics.
Posts to Index: For our purposes, we indexed two types of posts, and in total, we have approximately 100 posts. You should inspect where we employ the get_posts() function and adjust the query arguments as needed. For a swift configuration, you can refer to POST_TYPES in the Variables view.
Additional Contexts: Since we include extra context messages for accessibility, consider experimenting with the number of results we use. You can modify the topK variable in the HTTP request dispatched to Pinecone. Additionally, you have the option to load and utilize meta fields. To explore available WordPress functions, click here.
Coming Up Next
This article focused on the process of indexing your content in a vector database. In our subsequent articles, explore how to utilize this indexed data and seamlessly integrate semantic search results into your WordPress site using filters. Subsequently, we will delve into the creation of an AI-powered chatbot. This chatbot will empower your visitors to ‘chat’ with your content, revolutionizing their browsing experience. Stay tuned!

Related posts
Convoworks WP 0.24 – A Faster, Cleaner Editor on the Road to Version 1
Convoworks WP 0.24.00 enhances the editor with faster navigation, improved component search, and refreshed help documentation. It introduces secure API key storage and service management improvements, while refining the editor’s design for better usability. Deprecated platforms have been removed to streamline the core.
VIEW FULL POST
Convoworks, 2025 – Status and Next Steps
Convoworks started as a voice-workflow tool, survived the collapse of smart-speaker hype, and is now evolving into a modular, AI-first framework for WordPress. This update explains the cleanup in progress, the move toward agent infrastructure and natural-language building, and how you can follow along while v1 takes shape.
VIEW FULL POST


